




Liquid AI刚刚发布了LFM2.5-8B-A1B,这是一个基于混合专家(MoE)架构的8B参数模型。它的特别之处在于:虽然总参数量只有8B,但实际推理时只激活部分专家网络,使得性能接近更大规模的模型,同时保持了极低的资源消耗。
什么是MoE架构
混合专家(Mixture of Experts)是一种模型架构,核心思想是:模型内部有多个”专家”网络,每次推理时只激活其中一部分。这样做的好处是:
参数量大但计算量小:模型总参数量可以很大(提升容量),但每次推理只用到一小部分参数(降低计算成本)。
专业化分工:不同的专家可以专注于不同类型的任务,比如有的专家擅长代码,有的擅长自然语言。
LFM2.5-8B-A1B中的”A1B”表示”Active 1 Billion”,即每次推理只激活约10亿参数。这意味着虽然模型总参数是8B,但推理速度和资源消耗接近1B参数的密集模型。
性能表现
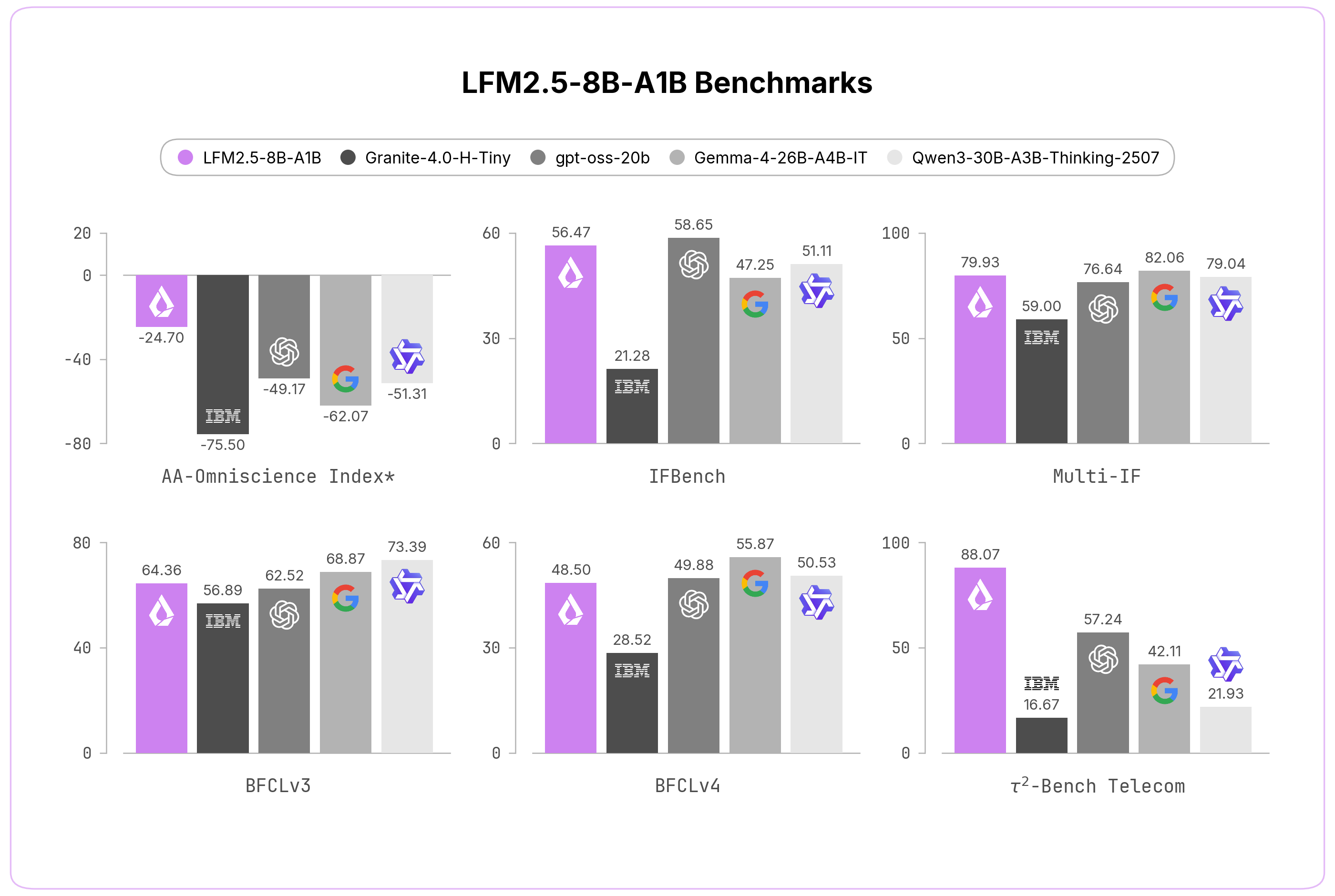
根据Liquid AI发布的基准测试结果,LFM2.5-8B在多项任务上表现优异:
工具调用:在函数调用和工具使用场景下,表现接近甚至超过一些更大的模型。这对于构建AI Agent来说非常重要。
指令遵循:在复杂指令理解和执行方面,得分与7B-13B级别的密集模型相当。
推理速度:在消费级GPU上,推理速度非常快,适合实时交互场景。
如何使用
LFM2.5-8B-A1B已经在多个主流推理框架中获得支持:
Hugging Face:可以直接通过transformers库加载:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("LiquidAI/LFM2.5-8B-A1B")
tokenizer = AutoTokenizer.from_pretrained("LiquidAI/LFM2.5-8B-A1B")
vLLM:支持高效推理部署:
python -m vllm.entrypoints.openai.api_server --model LiquidAI/LFM2.5-8B-A1B
llama.cpp:支持GGUF格式量化后在CPU上运行,适合没有GPU的用户。
适用场景
这个模型特别适合以下场景:
本地AI助手:在个人电脑上运行,无需联网即可使用AI功能。
AI Agent后端:工具调用能力强,适合作为AI Agent的推理引擎。
边缘设备部署:资源消耗低,可以在树莓派等边缘设备上运行。
API服务:推理速度快,适合搭建私有AI API服务。
与同类模型对比
目前市面上的轻量级MoE模型还不多。LFM2.5-8B的主要竞争对手包括Qwen2.5-7B、Llama3.1-8B等密集模型。在纯文本理解任务上,这些模型各有千秋;但在工具调用和资源效率方面,LFM2.5-8B有明显优势。
注意事项
MoE模型在某些推理框架中可能需要特殊配置。如果你遇到加载问题,建议检查框架版本是否为最新。另外,MoE模型的显存占用虽然低于同参数量的密集模型,但仍需要至少4-6GB的GPU显存。
本文参考来源:LFM2.5-8B-A1B: an Even Better on-Device Mixture-of-Experts | Liquid AI









暂无评论内容