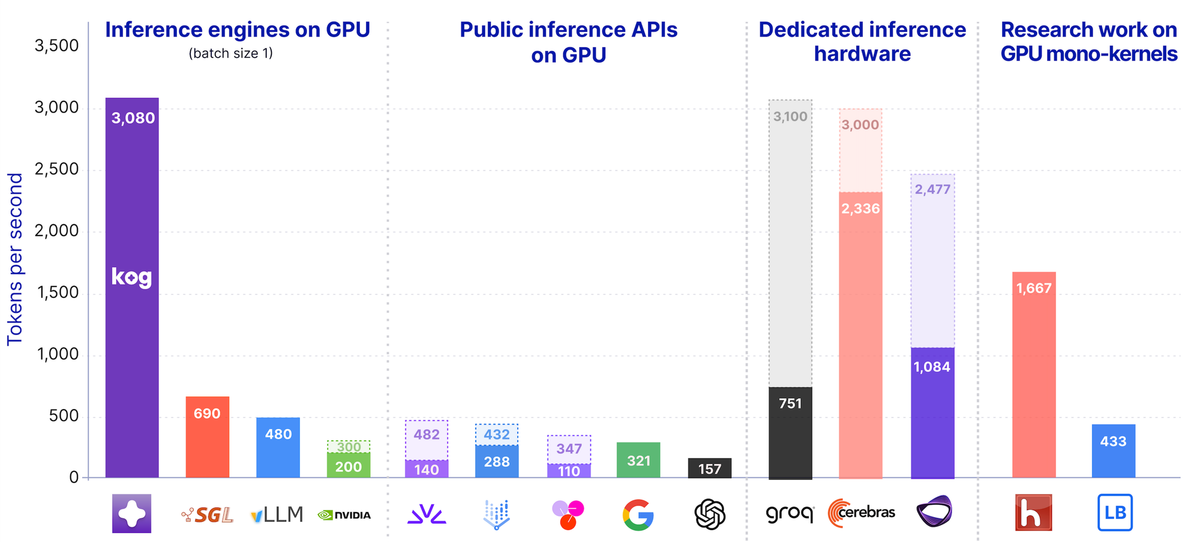





Kog AI最近发布了一篇技术博客,展示了在标准数据中心GPU上实现单请求3000 tokens/s推理速度的技术方案。这个速度已经接近专用推理硬件的水平,而用的是企业已经拥有的普通GPU。对于关注AI推理优化的站长和开发者来说,这篇文章有很多值得学习的地方。
为什么要关注单请求速度
推理性能通常有三个维度,很多人搞混了:
聚合吞吐量:所有用户每秒生成的token总数,衡量服务器利用率,奖励大批量处理。
首token延迟(TTFT):用户发送请求到第一个token返回的时间。
单请求解码速度:每个请求每秒生成的token数,这才是用户体验的直接指标。
Kog选择优化单请求速度,是因为AI Agent的工作模式本质上是顺序循环:检查→计划→编辑→测试→修改。每一步都依赖上一步的结果,无法并行化。工具调用时间有时占主导地位(测试要跑、网页要加载),但模型生成token的速度直接决定了Agent的迭代效率。
数字说明问题
如果一个Agent需要在工作流中生成50000个token:
– 100 tokens/s ≈ 8分钟
– 3000 tokens/s ≈ 17秒
这个差距不是”快一点”的问题,而是”能不能用”的问题。8分钟的等待让Agent的工作流变得不连贯,17秒则可以保持流畅的交互节奏。
核心原理:内存带宽是瓶颈
在batch size为1的自回归解码中,性能瓶颈不是计算能力(FLOPS),而是内存带宽。原因如下:
每生成一个token,模型的所有活跃权重都必须在GPU的内存层次结构中移动——从HBM到L2缓存再到计算单元。在FP16精度下,一个模型权重占2字节,贡献大约1次乘加运算(2 FLOPs),也就是约1 FLOP/byte。这远低于GPU的计算能力上限。
换句话说,GPU的算力在单请求场景下是严重过剩的,真正卡脖子的是把数据从显存搬到计算单元的速度。
这就是为什么内存带宽利用率(MBU)是单请求速度的核心指标,而不是模型FLOP利用率(MFU)。MFU可以通过批量处理多个请求来提升,但那解决的是吞吐量问题,不是单请求延迟问题。
好消息:GPU的内存带宽已经很高
8卡NVIDIA H200节点的内存带宽约30.7 TB/s。问题在于如何充分利用它。Kog的方案是通过架构/引擎/内核协同优化,最大化MBU。
他们的2B参数编码模型已经在公开技术预览中可用。虽然不是前沿大模型(他们优先优化速度而非规模),但在特定软件任务上经过微调后表现出色。
对站长和开发者的启示
1. 推理优化的关键是内存带宽,不是算力:如果你在做推理部署,关注GPU的内存带宽参数比关注TFLOPS更有意义。H200、A100这类高带宽显卡在单请求场景下优势明显。
2. 小模型+高速推理可能比大模型+慢速推理更实用:对于Agent场景,3000 tokens/s的2B模型可能比100 tokens/s的70B模型更有效,因为Agent需要快速迭代。
3. Batch size策略要分场景:如果是面向用户的实时交互,优化batch size 1的延迟;如果是批量处理任务,优化大批量的吞吐量。两者是不同的优化方向。
4. 量化不只是省显存:FP8量化不仅减少显存占用,还能提高内存带宽利用率(每字节贡献更多计算),一举两得。
实际部署建议
如果你想在自己的GPU服务器上优化推理速度:
– 优先选择高内存带宽的GPU(H200 > A100 > A6000)
– 使用FP8或INT8量化来提升MBU
– 关注vLLM、TensorRT-LLM等推理框架的MBU指标
– 对Agent场景,考虑使用小模型+微调的组合,而不是通用大模型
– 监控GPU的内存带宽利用率,而不是计算利用率
本文参考来源:Kog AI: Real-time LLM Inference on Standard GPUs | HN讨论(123分)










暂无评论内容