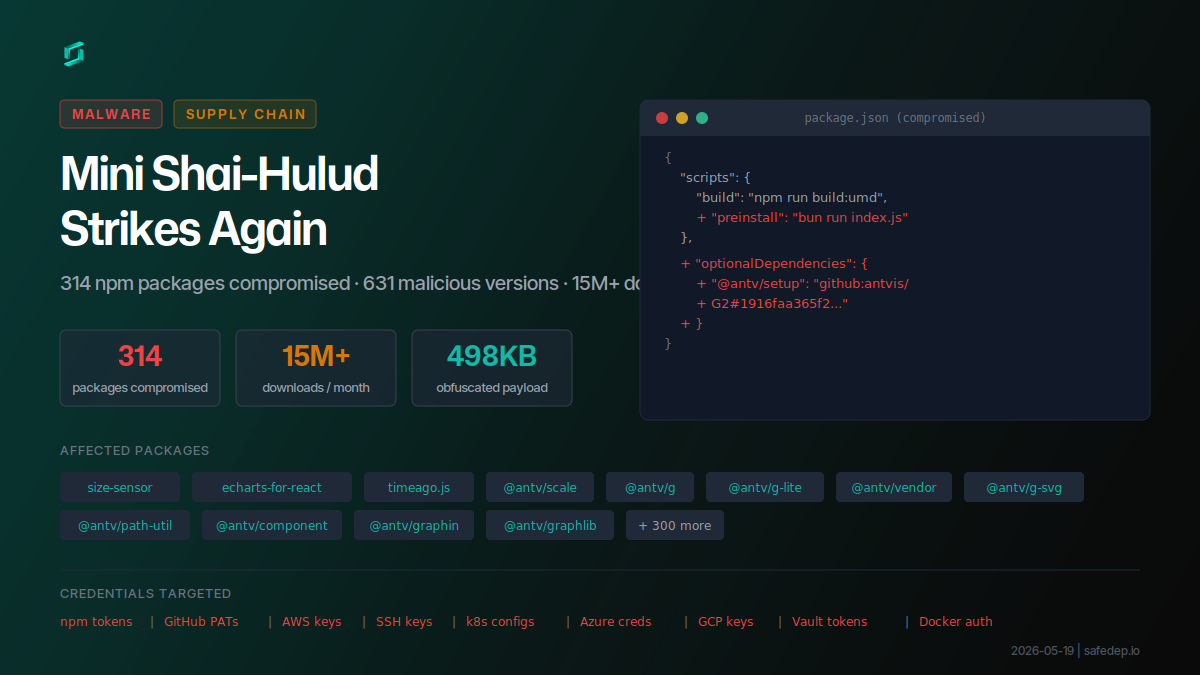





2026年5月19日,npm生态系统再次遭遇大规模供应链攻击。安全公司SafeDep披露,攻击者在22分钟内通过自动化脚本发布了637个恶意版本,波及317个npm包。这是继三周前SAP供应链攻击之后,”Mini Shai-Hulud”攻击团伙的又一次大规模行动。
事件经过
攻击者首先入侵了npm账户 atool(关联邮箱 [email protected]),然后利用自动化工具在极短时间内批量发布恶意版本。受影响的包中包括多个高下载量项目:
size-sensor:月下载量420万echarts-for-react:月下载量380万@antv/scale:月下载量220万timeago.js:月下载量115万- 以及数百个
@antv作用域下的包
恶意载荷分析
被注入的恶意代码是一个498KB的混淆Bun脚本,与此前SAP攻击中使用的”Mini Shai-Hulud”工具包特征一致:相同的扫描器架构、相同的凭证正则表达式、相同的混淆模式。
这个恶意脚本的窃取范围非常广泛:
- AWS全链条凭证(环境变量、配置文件、EC2 IMDS、ECS容器元数据、Secrets Manager)
- Kubernetes服务账户令牌
- HashiCorp Vault令牌
- GitHub Personal Access Tokens
- npm发布令牌
- SSH私钥
- 本地密码管理器保险库(1Password、Bitwarden、pass、gopass)
窃取的数据通过两个并行通道外传:一是通过被入侵令牌创建的公开GitHub仓库中的Git对象提交(User-Agent伪装为 python-requests/2.31.0);二是通过RSA+AES加密的HTTPS POST请求发送到 t.m-kosche[.]com,伪装成OpenTelemetry追踪数据。
CI/CD环境的危害
在CI环境中,恶意载荷会交换GitHub Actions OIDC令牌获取npm发布令牌,通过Sigstore(Fulcio + Rekor)使用窃取的身份签名制品,并将持久化代码注入 .github/workflows/codeql.yml。
更令人担忧的是,该载荷还会劫持Claude Code和Codex等AI编程工具,通过注入SessionStart钩子在每个AI会话中重新执行恶意代码。VS Code的 tasks.json 也被植入 "runOn": "folderOpen" 配置实现同样的效果。
如何检查你的项目是否受影响
立即运行以下命令检查项目依赖:
npm audit
npm audit --json | grep -i "malware\|compromised"使用SafeDep的 vet 工具扫描项目依赖中的已知恶意包:
# 安装 SafeDep vet
go install github.com/safedep/vet@latest
# 扫描当前项目
vet scan同时检查 package-lock.json 或 yarn.lock 中是否存在已知被攻陷的包版本。Socket.dev等供应链安全平台也会标记这些恶意包。
应对措施
立即行动
- 运行
npm audit检查项目是否依赖了受影响的包 - 将受影响的包更新到已修复的安全版本
- 如果曾使用受影响版本构建,检查构建产物中是否包含恶意代码
- 轮换所有可能暴露的API Key、Token和密码
长期防护
- 锁定依赖版本,使用精确版本号而非范围版本
- 启用npm provenance验证包的构建来源
- 始终提交并使用
package-lock.json - 将
npm audit集成到CI/CD流程中 - 为所有npm账户启用双因素认证
- 使用SafeDep vet等工具进行持续的供应链安全监控
影响评估
这次攻击的规模和手法都令人警醒。317个包同时被攻陷,涉及月下载量数百万的热门项目,影响面极广。攻击者对CI/CD环境和AI编程工具的针对性劫持,说明供应链攻击已经进入了新的阶段。
对于站长和开发者来说,这次事件再次提醒我们:不能完全信任第三方依赖,必须建立多层防御机制。定期审计依赖、锁定版本、启用2FA、集成安全扫描工具,这些都不是可选项,而是必选项。
本文参考来源:SafeDep Research – Mini Shai-Hulud Strikes Again: 317 npm Packages Compromised






 Timothy Gowers Blog – A Recent Experience with ChatGPT 5.5 Pro
Timothy Gowers Blog – A Recent Experience with ChatGPT 5.5 Pro



暂无评论内容