WordPress
wordpress主题
wordpress插件
技术分享
DeepSeek
软件/源码
网创项目
课程资源
影视资源
电影
电视剧
发布
发布文章
创建话题
创建版块
发布帖子
开通会员
开通黄金会员
全站资源折扣购买
部分内容免费阅读
一对一技术指导
VIP用户专属QQ群
开通黄金会员
开通钻石会员
全站资源折扣购买
部分内容免费阅读
一对一技术指导
VIP用户专属QQ群
开通钻石会员
开通会员 尊享会员权益
登录
注册
找回密码
WordPress
wordpress主题
wordpress插件
技术分享
DeepSeek
软件/源码
网创项目
课程资源
影视资源
电影
电视剧
开通会员 尊享会员权益
登录
注册
找回密码
最新发布
第23页
排序
更新
浏览
点赞
评论
Coursera和Udemy正式合并:在线教育行业大洗牌,学习者和站长需要知道什么
AI资讯
48天前
0
30
13
从FiveThirtyEight存档看网站数据备份:21000+页面被互联网档案馆完整保存
网站工具
40天前
0
47
13
字节跳动AI基础设施支出增至2000亿元,加码国产AI芯片投入
AI资讯
51天前
0
28
13
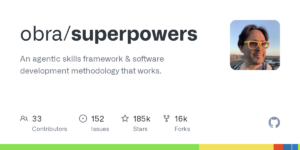
Superpowers:给AI编程Agent加上可复用的技能包,GitHub星标突破18万
开源项目
# AI Agent
# Superpowers
# 开发效率
50天前
0
34
13
Moltworker:不依赖运行时的下一代 SSR JavaScript 框架
网站工具
49天前
0
43
13
亚马逊员工被曝伪造AI使用量:当token消耗变成KPI考核指标
AI资讯
43天前
0
27
13
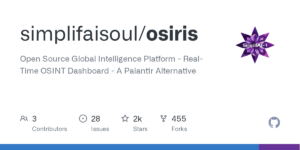
Osiris:开源全球情报监控平台,实时追踪全球事件的OSINT工具
开源项目
37天前
0
36
13
2026年AI Agent多Agent编排模式详解:四种子Agent架构实战
AI教程
# AI Agent
# LLM
# Subagent
51天前
0
24
13
2026年免费云服务器和AI API额度汇总:站长和开发者能白嫖的资源清单
云服务
49天前
0
45
13
OfficeCLI:让 AI Agent 操作 Word/Excel/PPT 的开源命令行工具教程
开源项目
46天前
0
62
13
加载更多
发布文章
创建话题
创建版块
发布帖子
在手机上浏览此页面
登录
没有账号?立即注册
手机号或邮箱
验证码
发送验证码
记住登录
账号密码登录
登录
用户名/手机号/邮箱
登录密码
记住登录
找回密码
|
免密登录
登录
注册
已有账号,立即登录
设置用户名
手机号或邮箱
验证码
发送验证码
设置密码
重复密码
注册